Wars Blog
Blog
Mirrors
Gallery
Draw
Git
Search
登录
or
注册
Category
Coding
Elasticsearch 笔记
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-15
900
0
Coding
Redis 优化方案
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-14
1.22k
0
Coding
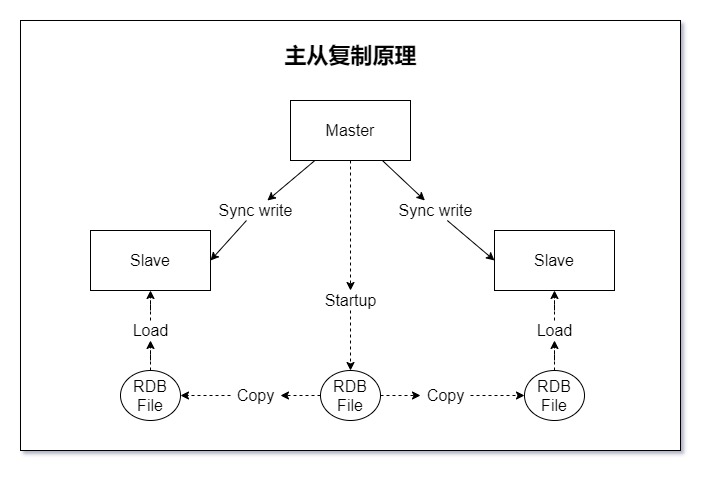
Redis
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-14
1.02k
0
Coding
ETCD 集群搭建
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-07-30
1.15k
0
Coding
MongoDB笔记
MongoDB MongoDB体系结构 传统SQL数据库:实例(N):数据库(1),这种情况在Oracle中称为RAC ...
Post on 2019-02-02
815
0
X