

本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
访问 https://creativecommons.org/licenses/by-sa/4.0/ 查看该许可协议。
JVM 笔记
本文都基于 Hotspot 编写
1) JVM 内存
1.1) JVM 内存结构
- 线程共享
- 堆
- 方法区
- 线程隔离
- 虚拟机栈
- 本地方法栈
- 程序计数器
1.2) 堆
1.2.1) JDK 1.8 以前
- 新生代
- Eden
- Survivor 1
- Survivor 2
- 老年代
- Tenured
- 持久代
- Perm Gen
1.2.1) JDK 1.8 后
1.8 后将 Perm Gen 持久代替换成了 Metaspace 元空间:
从使用堆内存 升级为 直接使用 OS 内存资源
- 新生代
- Eden
- Survivor 1
- Survivor 2
- 老年代
- Tenured
- 元空间
- Metaspace
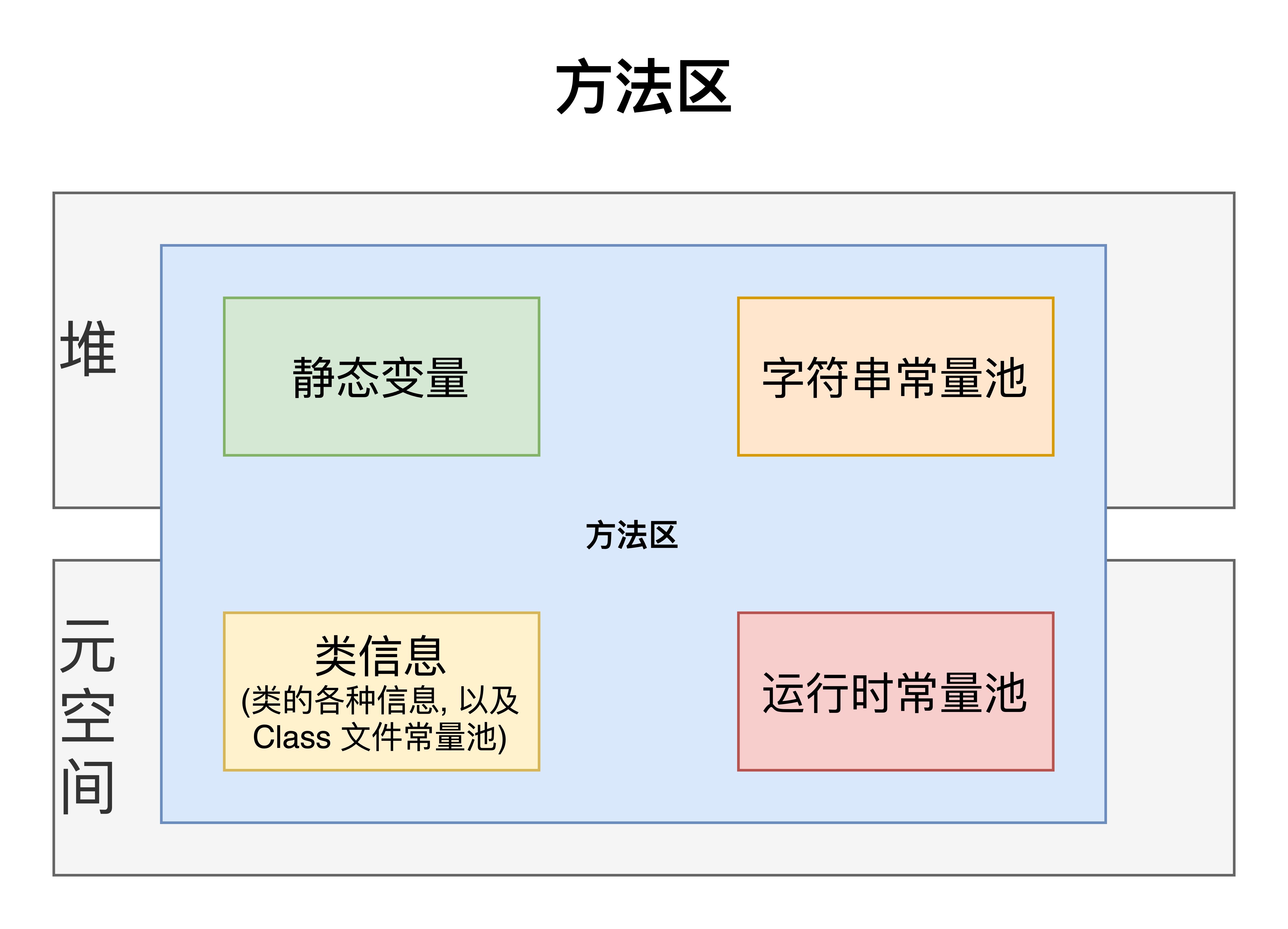
1.3) 方法区
有两个陌生的常量池: Class 常量池主要存放类加载到内存之后的常量等, 然后将这些常量继续加载至运行时常量池
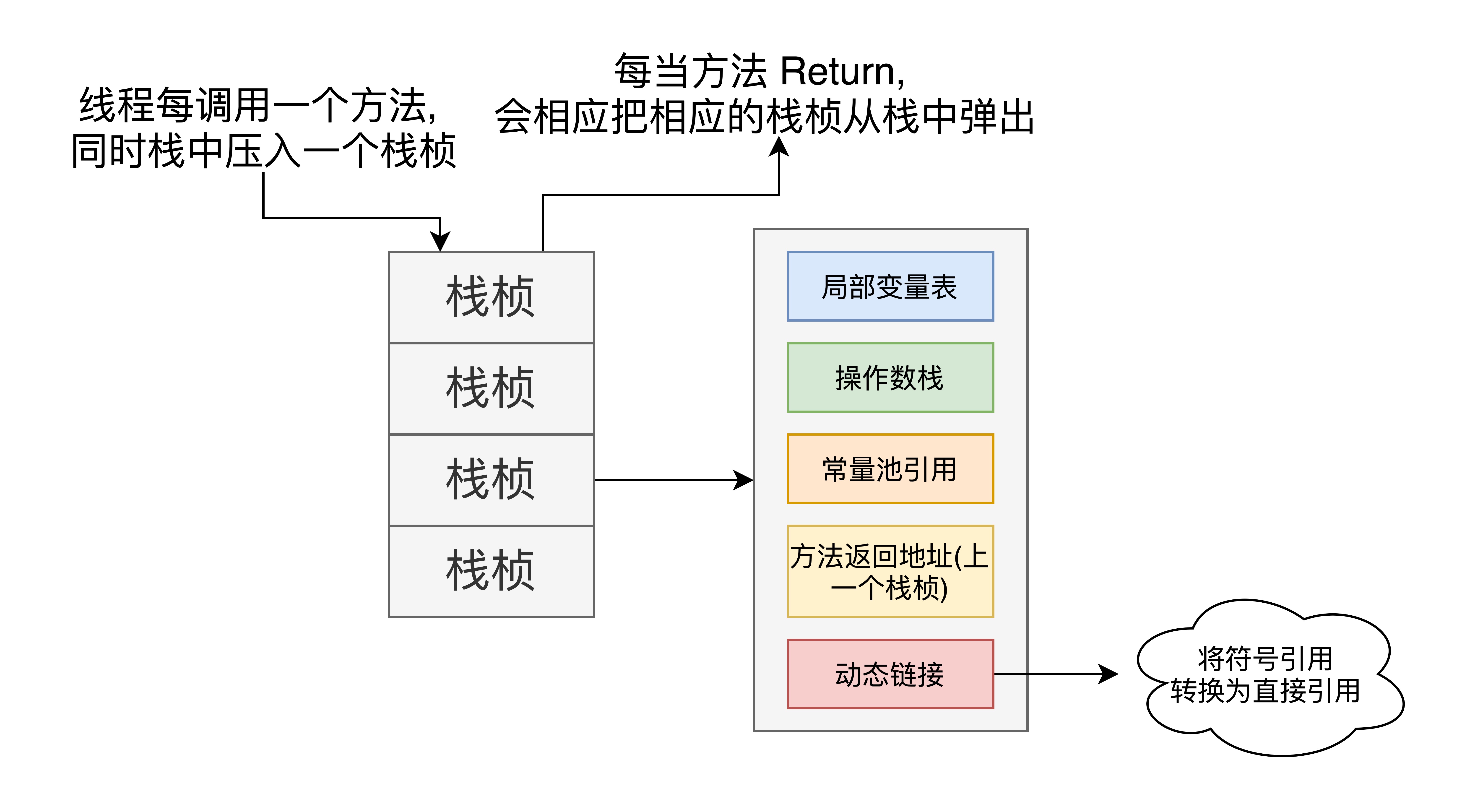
1.4) 虚拟机栈
当创建一个线程时, 会建立对应此线程的虚拟机栈, 管理本地方法, 一图流:
1.5) 本地方法栈
与虚拟机栈类似, 但只管理 Native 方法, 这里不细讲了.
1.6) 程序计数器
与前两者一致, 都是线程级的, 主要记录当前线程的执行到了哪个位置, 供于多线程切换后运行状态的恢复.
2) 类加载
Hotspot 1.8 类加载过程如下图:
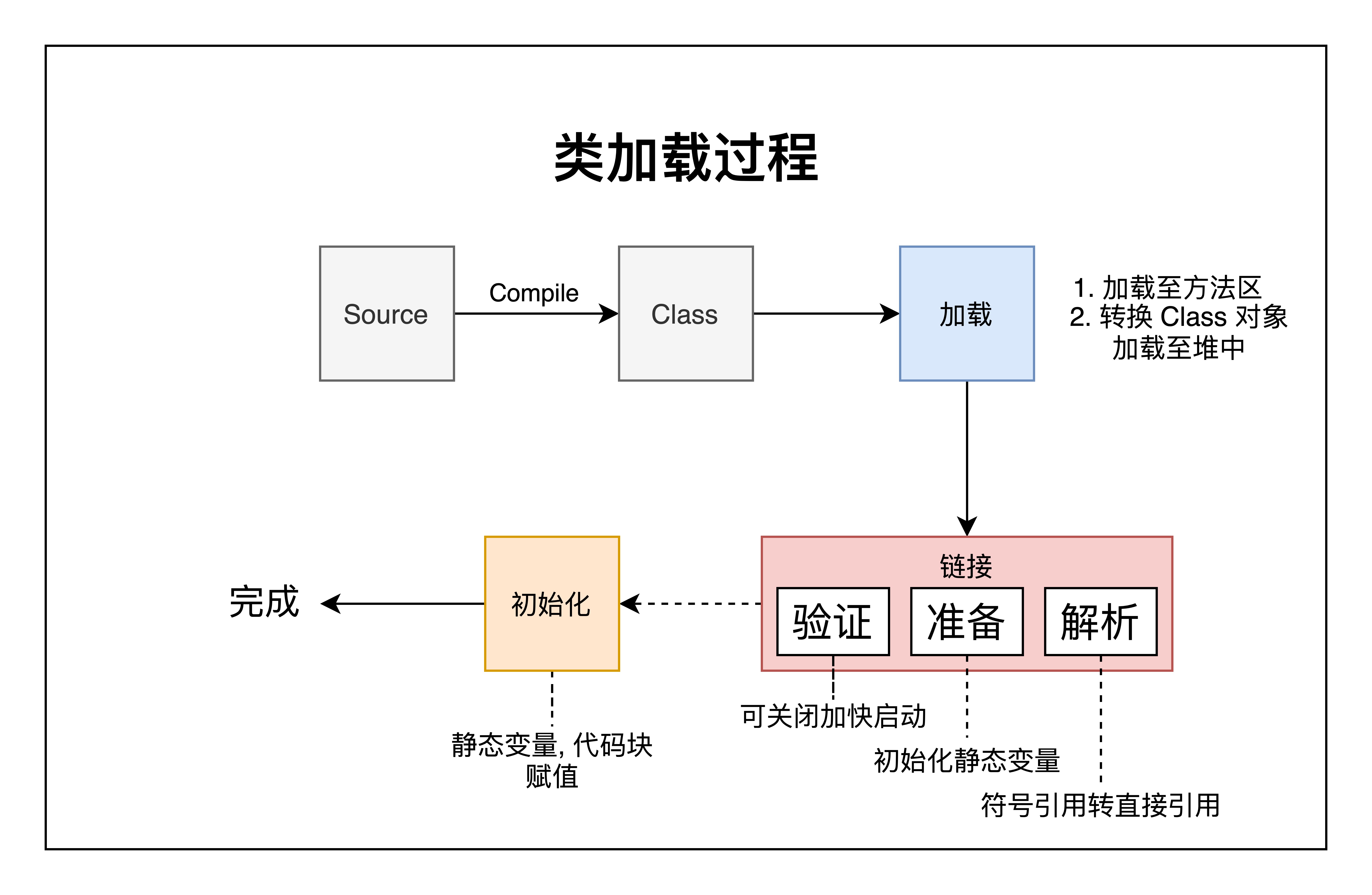
如果确认项目能正常加载, 可以用 -Xverify:none 关闭链接阶段验证步骤提高启动速度, 可应用在 IDEA 之类的 Java IDE 上.
3) 编译器优化
3.1) 运行模式优化
JVM 一共有三种运行模式, 默认 Mixed 混合模式:
- -Xint: 解释模式
- -Xcomp: 编译模式, 优先以编译模式运行
- -mixed: 混合模式, 用 JIT(即时编译器) 将热点代码编译提高启动速度
- 分层编译优化
3.2) JIT 优化
JIT(Just-In-Time Compiler) 即时编译器, 由 JIT 来即时决定调用代码是否需要编译, Hotspot 中提供两个 JIT, C1 和 C2
3.2.1) JIT_C1(Client Compiler)
- 只局部优化, 简单快速
- 启动速度高, 适合做 GUI 等 Client 应用
3.2.2) JIT_C2(Server Compiler)
- 相比 C1 优化更全面
- 启动速度慢, 适合做执行时间较长或追求性能的程序
3.3) 热点代码优化
被判断为热点代码则会被 JIT 编译成字节码执行, 反之则解释执行.
以下的代码为热点代码:
- 重复出现在栈顶的方法
- 计数器探测
- 方法调用计数器(Invocation Counter): 可通过
-XX:CompileThreshold=x设置阈值- 统计方法被调用次数, 不开启分层编译时, C1 阈值 1500, C2 阈值 10000 次
- 每过一段时间会在 GC 时, 顺便发生热度衰减导致阈值减半
-XX:-UseCounterDecay关闭热度衰减-XX:COunterHalfLifeTime=x设置热度衰减周期
- 回边计数器(Back Edge Counter): 可通过
-XX:OnStackReplacePercentage=X设置阈值- 统计循环代码执行次数, 不开启分层编译时, C1 阈值 13995, C2 阈值 10700 次
- 方法调用计数器(Invocation Counter): 可通过
当开启分层编译时, JVM 根据当前待编译方法数, 编译线程数动态调整阈值, 上述两个 JVM 参数会失效
3.4) 分层编译优化
分层编译一共有 5 种级别, 根据代码的热点程度使用相应级别优化代码:
- 解释执行
- 简单 C1 编译, 不开启 Profiling JVM 性能监控
- 受限的 C1 编译, Profiling 只监控方法调用次数, 循环回边执行次数
- 完全 C1 编译, 会使用 C1 的所有 Profiling 监控
- C2 编译, 某些情况会根据性能监控信息进行一些非常激进的优化
可以通过以下 JVM 参数限制级别:
- 仅使用 C1:
-XX:+TieredCompilation -XX:TieredStopAtLevel=1- TieredStopAtLevel 即分层停止级别, 若设置为 3 则只使用 0,1,2,3 级编译
- 仅使用 C2:
-XX:-TieredCompilation, 关闭分层编译, 仅使用 0,4 级别优化
3.5) 方法内联优化
JVM 会使用内联优化, 将满足条件的目标代码, 尝试内联(复制)至调用处, 减少入栈出栈开销:
- 方法体足够小
- 热点方法体阈值 325 字节, 可用
-XX:FreqInlineSize=x修改 - 非热点方法体阈值 35 字节, 可用
-XX:MaxInlineSize=x修改
- 热点方法体阈值 325 字节, 可用
- 目标方法运行时的实现可以被唯一确定
方法内联带来的问题: 方法内联实际上是空间换时间, 如果内联过多可能导致 CodeCache 溢出, 使得 JVM 降级解释模式运行
| 以下还有一些其他的方法内联参数: | 参数名 | 默认 | 说明 |
|---|---|---|---|
| -XX:+Printlnlining | - | 打印内联详情, 该参数需和 -XX:+UnlockDiagnosticVMOptions 配合使用 | |
| -XX:+UnlockDiagnosticVMOptions | - | 打印 JVM 诊断相关的信息 | |
| -XX:MaxInlineSize=n | 35 | 如果非热点方法的字节码超过该值, 则无法内联, 单位字节 | |
| -XX:FreqInlineSize=n | 325 | 如果热点方法的字节码超过该值, 则无法内联, 单位字节 | |
| -XX:InlineSmallCode=n | 1000 | 目标编译后生成的机器码代销大于该值则无法内联, 单位字节 | |
| -XX:MaxInlineLevel=n | 9 | 内联方法的最大调用帧数(嵌套调用的最大内联深度) | |
| -XX:MaxTrivialSize=n | 6 | 如果方法的字节码少于该值,则直接内联,单位字节 | |
| -XX:MinInliningThreshold=n | 250 | 如果目标方法的调用次数低于该值,则不去内联 | |
| -XX:LiveNodeCountlnliningCutoff=n | 40000 | 编译过程中最大活动节点数(IR节点)的上限,仅对C2编译器有效 | |
| -XX:InlineFrequencyCount=n | 100 | 如果方法的调用点(call site)的执行次数超过该值,则触发内联 | |
| -XX:MaxRecursiveInlineLevel=n | 1 | 递归调用大于这么多次就不内联 | |
| -XX:+InlineSynchronizedMethods | 开启 | 是否允许内联同步方法 |
3.5) 标量替换 / 栈上分配
| -XX:+DoEscapeAnalysis | 开启 | 是否开启逃逸分析 |
| -XX:+EliminateAllocations | 开启 | 是否开启标量替换 |
| -XX:+EliminateLocks | 开启 | 是否开启锁消除 |
4) GC 优化
我们可以根据各种场景下的需求, 来选择垃圾回收策略, 如:
- 内存不足场景: 提高对象的回收效率, 腾出更多内存
- CPU 资源不足: 降低高并发时垃圾回收频率, 充分利用 CPU 资源提高并发量
4.1) GC 在哪回收
上文提到 JVM 的内存结构可以得知, (虚拟机栈,本地方法栈,程序计数器) 都是线程隔离的, 对象会随着栈入栈出自动销毁, 所以它们不需要考虑线程隔离.
而线程共享的(堆,方法区), 则是会发生 GC 的部分:
- 堆: 回收对象
- 方法区: 回收常量和未被使用的类
4.2) 垃圾计算算法
Java 默认使用的垃圾计算算法是可达性分析算法, 我们还可以了解以下引用计数法:
4.2.1) 引用计数法
记录对象的被引用的次数, 当计数器归 0, 即回收, 无法解决循环引用问题
4.2.1) 可达性分析
可达性分析即: 被 GCRoots 直接或间接引用则可达, 反之不可达, 可以回收.
GCRoots 有以下几类, 可达性可以理解为堆外指向堆内的引用:
- 虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI 引用的对象
引用又有以下几种:
- 强引用
- 软引用
- 弱引用
- 虚引用
不可达对象回收流程:
- 不可达的对象首先会被标记死缓
- 判断该对象有无必要执行(重写)
finalize(), 如不需要则回收
- 判断该对象有无必要执行(重写)
- 若有必要执行
finalize(), JVM 会创建一个低优先级线程执行其- 若
finalize()中的代码重新使该对象建立引用, 则放弃回收
- 若
4.3) 垃圾回收算法
三种常用基础算法:
- 标记清除算法: 会产生碎片, 放不下大对象导致溢出
- 标记需要被回收的对象
- 清理需要被回收的对象
- 标记整理/压缩算法: 相比标记清除避免内存碎片
- 标记需要被回收的对象
- 把存活对象移动到一起
- 剩余区域回收
- 复制算法:
- 需要两块一样大小的内存区域 AB, 只使用其中一块
- 将 A 存活对象复制到 B, 切换使用空间至 B
- 清空 A
- 将 B 存活对象复制到 A, 切换使用空间至 A
- 清空 B
- ....
三种常用基础算法对比:
| 算法 | 优点 | 缺点 |
|---|---|---|
| 标记清除 | 实现简单 | 存在内存碎片, 分配内存开销 |
| 标记整理 | 无碎片 | 整理开销 |
| 复制 | 性能好, 无碎片 | 内存利用率低 |
两种综合算法:
- Java 分代收集算法:
- 增量算法:
4.4) 垃圾收集器
新生代收集器(复制算法):
- Serial (Client 模式默认收集器):
- 单线程
- 简单, 高效
- 收集全程 Stop The World
- ParNew (Serial 多线程版)
- 多线程
- 线程数:
-XX:ParallelGCThreads=x - 主要和 CMS 配合使用
- Parallel Scavenge (吞吐量优先收集器)
- 多线程
- 可控制回收吞吐量
- 回收最大停顿时间(尽量保证):
-XX:MaxGCPauseMilis - 吞吐量大小, 设置回收时间不超过运行时间的 1/(1+n):
-XX:GCTimeRatio - 自适应 GC:
-XX:+UseAdptiveSizePolicy- 开启后无需手动设置新生代大小(-Xmn), Eden/Survivor 区比例(-XX:SurvivorRatio) 等参数
- 回收最大停顿时间(尽量保证):
老年代收集器(标记清除算法):
- Seria Old
- CMS 收集器的后备收集器
- Parallel Old
- CMS(Concurrent Mark Sweep)
- 并发收集器
- 老年代占比触发阈值:
-XX:CMSInitiatingOccupancyFraction=-1
CMS 执行流程:
- 初始标记
- 标记 GC Roots 直接关联对象
- Stop The World
- 并发标记
- 标记 GC Roots 关联的所有对象
- 并发执行, 无 Stop The World
- 并发预清理
- 重新标记上阶段中, 引用被更新的对象
- 并发执行
- 关闭此阶段:
-XX:-CMSPrecleaningEnable=true
- 并发可终止预清理
- 与上阶段一致
- 当 Eden 的使用量大于阈值:
-XX:CMSScheduleRemarkEdenSizeThreshold=2M才执行 - 控制预清理阶段结束时机
- 扫描时间阈值(s):
-XX:CMSMaxAbortablePrecleanTime=5 - Eden 占比阈值:
-XX:CmsScheduleRemarkEdenPenetration=50
- 扫描时间阈值(s):
- 重新标记
- 修正并发标记期间, 标记发生变动的对象标记
- Stop The World
- 并发清理
- 直接清除被标记对象
- 并发执行
- 并发重置
- 清理本次 CMS GC 的长下文信息, 为下一次 GC 做准备
G1 收集器
- Region 式内存区块分布
- CMS 替代品
- Java9 后删除了 CMS
- 复制算法, 没有碎片
评论(0)
暂无评论