

本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
访问 https://creativecommons.org/licenses/by-sa/4.0/ 查看该许可协议。
DB 调优
- DB 调优
本文基于 MySQL 编写,兼容版本 5.7+
1) 调优数据库纬度
从上往下成本依次递减, 从上往下效果依次递增, 尽量从下往上优化, 提高投入产出比
- 硬件和系统调优
- 硬件
- 硬件配置
- OS 配置
- 内核参数如 swappiness 等
- MySQL 自身调优
- 数据库参数配置
- 性能参数如 buffer 等
- 表结构
- 良好的表结构
- SQL 以及索引
- 良好 SQL
- 高效索引
- 架构调优
- 系统架构
- 读写分离
- 高可用
- 实例个数
- 分库分表
- 数据库选择
- 业务需求
- 拒绝不合理的需求, 提出优化方案
2) 性能分析
2.0) 数据准备
基于 MySQL 官方测试数据库, 可按照 README 安装:
https://github.com/datacharmer/test_db
2.1) 慢查询分析
2.1.1) MySQL 慢查询日志配置
加入 my.cnf 中 mysqld 重启; 或在 clinet 中 set global 临时生效.
- slow_query_log: 开启日志输出
- slow_query_log_file: 默认如 /var/log/mysql/xxxx.slow_log, 慢日志存放路径
- log_output(FILE, TABLE): 默认 FILE, 输出至 mysql.slow_log, 可以组合使用如: FILE,TABLE
- long_query_time: 默认 10, 即执行时间超过 10 秒记录为慢查询
- long_queries_not_using_indexes(OFF, ON): 默认 OFF, 是否将未使用索引 SQL 同时记录
- long_throttle_queries_not_using_indexes: 默认 0, 与 long_queries_not_using_indexes 搭配使用, 限制每分钟写入未使用索引 SQL 数量
- min_examined_row_limit: 默认 0, 慢查询 SQL 行数超过此阈值才记录
- log_slow_admin_statements(OFF, ON): 默认 OFF, 是否记录管理语句(ALTER TABLE, ANALYZE TABLE, CHECK TABLE, CREATE INDEX, DROP INDEX, OPTIMIZE TABLE, REPAIR TABLE)
- log_slow_slave_statements(OFF, ON): 默认 OFF, 是否记录 Slave 节点做主从复制时, 超过 long_query_time 时间的复制查询
- log_slow_extra(OFF, ON): 默认 OFF, 仅当日志输出为文件时有效, 额外输出一些额外 log
2.1.2) MySQL 慢查询日志分析
2.1.3) TABLE 类型日志分析
SELECT * FROM `mysql`.slow_log;终端查询 SQL 会显示如下, 可以使用其他工具如 DataGrip 查看具体 SQL
+----------------------------+---------------------------+-----------------+-----------------+-----------+---------------+-----------+----------------+-----------+-----------+------------------------------------------------------------+-----------+
| start_time | user_host | query_time | lock_time | rows_sent | rows_examined | db | last_insert_id | insert_id | server_id | sql_text | thread_id |
+----------------------------+---------------------------+-----------------+-----------------+-----------+---------------+-----------+----------------+-----------+-----------+------------------------------------------------------------+-----------+
| 2020-10-17 22:56:21.693516 | root[root] @ localhost [] | 00:00:00.004481 | 00:00:00.000000 | 0 | 0 | employees | 0 | 0 | 1 | 0x73657420676C6F62616C20736C6F775F71756572795F6C6F673D4F4E | 22 |
| 2020-10-17 22:56:28.742718 | root[root] @ localhost [] | 00:00:00.165174 | 00:00:00.000109 | 300024 | 300024 | employees | 0 | 0 | 1 | 0x73656C656374202A2066726F6D20656D706C6F79656573 | 22 |
+----------------------------+---------------------------+-----------------+-----------------+-----------+---------------+-----------+----------------+-----------+-----------+------------------------------------------------------------+-----------+2.1.4) FILE 类型日志分析
日志文件存放路径可以使用如下 SQL 查询:
show variables LIKE '%slow_query_log%';日志文件不好直接浏览, 可以使用 MySQL 自带工具 mysqldumpslow 分析, 使用方法可以参考 mysqldumpslow --help:
mysqldumpslow -s t -t 10 -g "ORDER BY" /usr/local/var/mysql/warsdeiMac-slow.log2.1.3) EXPLAIN 分析 SQL 执行计划
使用 EXPLAIN 加上 SQL 即可分析 SQL 的执行计划如: explain SELECT * FROM employees;
输出格式一共有三种, 可以在 EXPLAIN 后拼上 FORMAT=(TREE,JSON) 使用其他两种.
默认输出的信息列含义解释如下:
- id: 值越大越先执行, 相同 id 则从上往下执行.
- select_type: 此步骤查询类型, 参考: https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain_select_type
- table: 此步骤查询的表名或别名
- partitions: 匹配查询记录的分区, 无分区则 null
- type: 连接类型, 效率从上往下依次递减, 含义参考: https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-join-types
- system
- const
- eq_ref
- ref
- fulltext
- ref_or_null
- index_merge
- unique_subquery
- index_subquery
- range
- index
- ALL
- possible_keys: 此步骤可调用的所有索引
- key: 实际使用的索引
- key_len: 索引使用的字节数, 可判断索引使用情况, 越小越好
- ref: 代表此步骤中, 与 key 列(实际使用的索引)进行比较的列
- rows: 估计将扫描的行数
- filtered: 符合查询条件数据所占百分比
- Extra: 其他信息, 参考: https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-extra-information
还可以在 SQL 结尾使用 SHOW WARNING, 查看扩展信息, 这里不深究.
2.1.4) SHOW PROFILE 分析各阶段开销
SHOW PROFILE 已经被废弃, 但是 PERFORMANCE_SCHEMA 使用过于繁琐, 依然建议使用 SHOW PROFILE.
- SELECT @@have_profiling;
是否支持 SHOW PROFILE - SELECT @@PROFILING;
是否已启用 - SET profiling=1/0;
开启或关闭, 分析完成请关闭此功能降低性能损耗 - SHOW PROFILES;
查看最近执行 15 条 SQL 耗时, 可通过SET profiling_history_size=x调整数量 - SHOW PROFILE [type, ...] FOR QUERY {Query_ID}
- Query_ID 通过 SHOW PROFILES 获得
- type:
- ALL
- BLOCK IO
- CONTEXT SWITCHES
- CPU
- IPC
- MEMORY
- PAGE FAULTS
- SOURCE
- SWAPS
2.1.5) OPTIMIZER_TRACE
待完善
3) 索引
3.1) 常见 Tree 数据结构
3.1.1) 二叉树
左边叶子节点始终比右边节点小, 因为无法保证左右平衡, 所以上界 O(n)
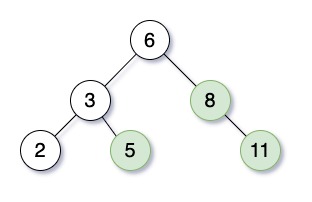
3.1.2) 平衡二叉树
左边叶子节点始终比右边节点小, 加入平衡算法改变树结构保证平衡, 所以上界 O(logn)
3.1.3) B-tree
| 算法 | 平均 | 最差 |
|---|---|---|
| 空间 | O(n) | O(n) |
| 搜索 | O(log n) | O(log n) |
| 插入 | O(log n) | O(log n) |
| 删除 | O(log n) | O(log n) |
图有点难画, 转自维基百科:

- m 为树的层数
- 根节点的子节点个数为 2 <= x <= m
- 中间节点的子节点个数为 m/2 <= y <= m
- 有 k 个子节点的非叶子节点有 k - 1 个键
3.1.4) B+tree
相对于 B-tree, 适合范围查找
图有点难画, 转自维基百科:
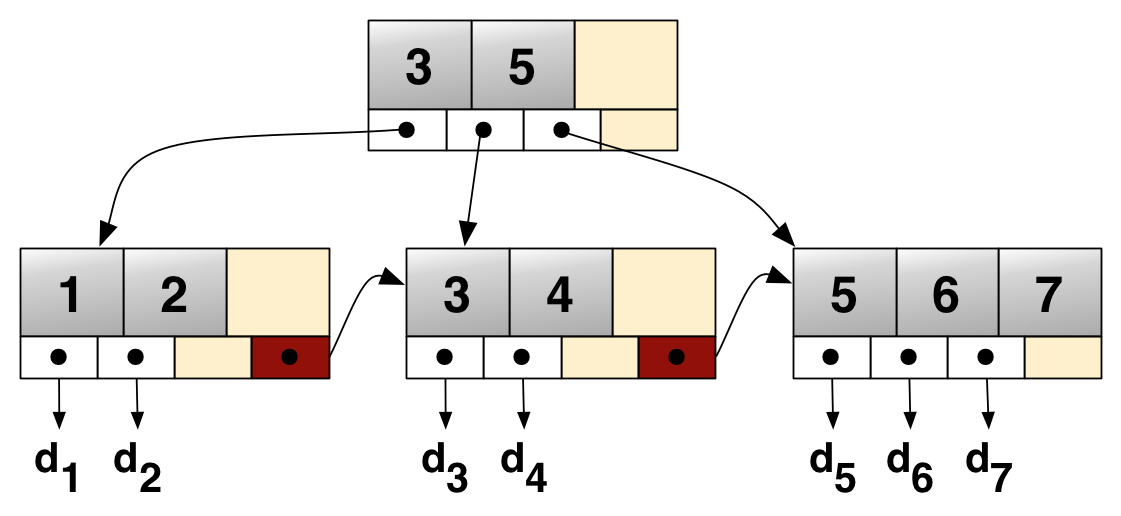
- 与 B-tree 最大的区别是各节点中包含了所有父节点的关键字, 有序链表存储
- 所有叶子节点中间有指针相连
3.2) MySQL 索引类型
3.2.1) InnoDB vs MyISAM
InnoDB 和 MyISAM 数据结构都默认使用 B+tree 实现
- InnoDB: 聚簇索引
- 叶子节点索引和数据存储在一起
- MyISAM: 非聚簇索引
- 的叶子节点只存储数据指针
3.2.2) Hash
上界 O(1)
转自慕课网架构师直通车:
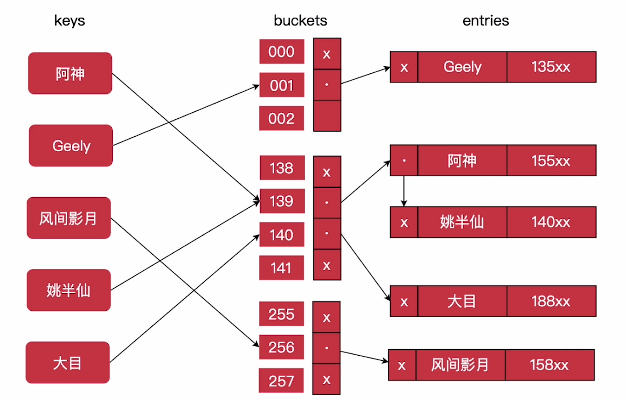
3.2.2.1) MySQL Hash 索引
默认只支持 Memory 引擎, InnoDB 可以通过 innodb-adaptive_hash_index 参数开启 ‘自适应 Hash 索引’, 默认打开
CREATE TABLE hash_test(
name varchar(55) not null,
age tinyint(4) not null,
key using hash(name)
)engine = memory;3.2.3) 空间索引
MySQL 5.7 后支持 InnoDB, 之前只支持 MyISAM, 建议使用 PostgreSQL 玩空间索引
3.2.4) 全文索引
MySQl 5.7 后支持中文,之前通常搭配搜索引擎使用, 建议使用搜索引擎
3.3) 索引限制
3.3.1) 匹配规则支持
- 完全匹配: WHERE name = 'wars'
- 范围匹配: WHERE age > 18
- 前缀匹配: WHERE name LIKE 'w%'
3.3.1) B-tree / B+tree 组合索引限制
index(name, age, sex)
- 组合索引查询条件不包括最左列(name),则无法使用索引
- 组合索引若不连续使用(WHERE name='a' AND sex=1),只能使用到 name 索引
-
组合索引查询中如有列范围(模糊)查询(WHERE age>1 AND sex=1), 右边列都玩法使用索引(sex)
3.3.2) Hash 索引限制
- 无法使用排序
- 不支持范围/模糊查询
- 不支持部分索引列匹配查找
3.4) 创建索引原则
建议创建场景:
- SELECT 中频繁 WHERE 字段
- UPDATE/DELETE 中非主键 WHERE 条件
- ORDER BY/GROUP BY 字段
- DISTINCT 字段
- 唯一约束字段
- 多表连接字段,务必类型一致(避免隐式转换)
不建议创建场景:- WHERE 中用不到的字段
- 表记录过少
- 表中大量重复数据
- 频繁更新的字段,会产生索引维护开销
3.5) 索引失效
- WHERE 中对索引列使用了表达式或函数
- 尽量避免使用左模糊, 可考虑转搜索引擎
- OR 条件左右侧有无索引字段,引起全表扫描
- WHERE 条件和索引列类型不一致
- WHERE 条件字段含有 NULL 值, 无法索引, 建议将表字段都定义成 NOT NULL
3.6) 索引调优
3.6.1) 长字段索引调优
对于长字段列, 可以新建一列 Hash 列作为索引, 在插入时, 可以计算该字段值的 Hash, 然后与该字段一同插入表中.
查询时直接计算 Hash 值直接查 Hash 列即可.
3.6.1.1) 无法模糊查询问题
但是这种 Hash 索引无法模糊查询, 所以可以引进前缀索引:
-- 5 代表使用该列的前几个字符进行索引
ALTER TABLE employees ADD KEY(first_name(5));那么前缀多少比较好呢, 可以使用一个完整列选择性公式计算:
-- 计算此列的最大选择性积分
SELECT COUNT(DISTINCT first_name) / COUNT(*) FROM employees;
-- 计算当前缀索引长度为 x 时, 选择性积分, 可以依次递增计算次列合适的长度
SELECT COUNT(DISTINCT LEFT(first_name, x)) / COUNT(*) FROM employees;还可以新增一个字段反转列, 建立前缀索引, 即可实现后缀索引
评论(0)
暂无评论