Wars Blog
Blog
Mirrors
Gallery
Draw
Git
Search
登录
or
注册
category
Coding
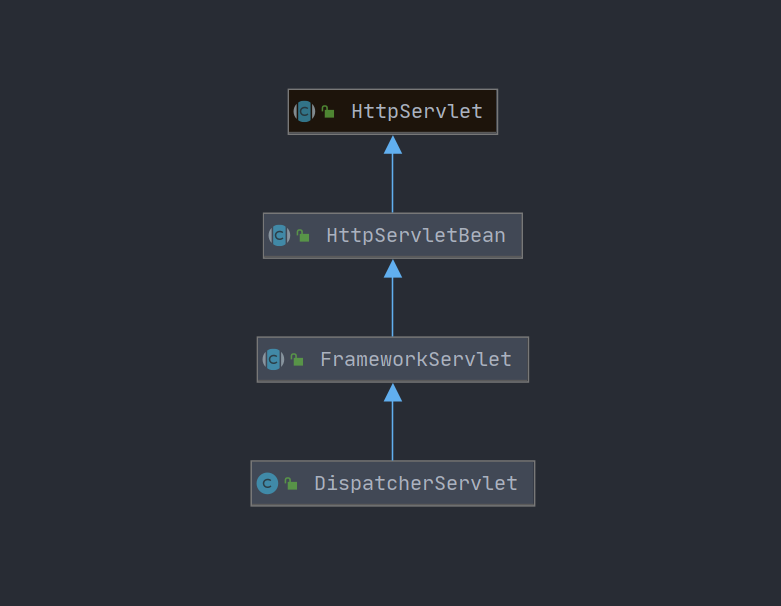
SpringMVC 源码剖析(更新中)
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-25
585
0
Coding
SpringBoot 自动配置 / 自动装配 源码剖析
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-23
581
0
Coding
SpringCloud 优化(更新中)
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-21
452
0
Coding
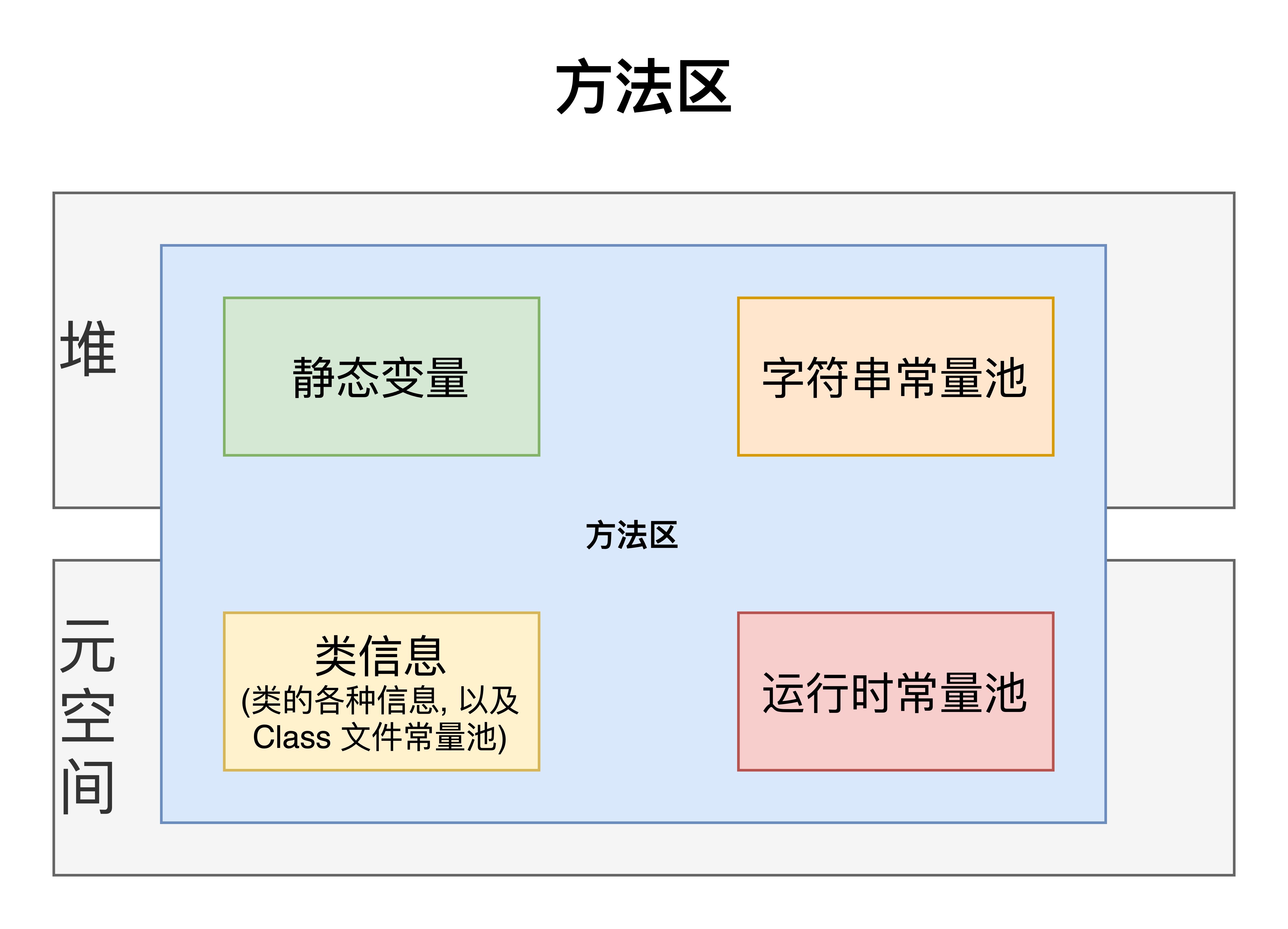
JVM
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-20
328
0
Coding
MySQL 调优
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-18
561
0
Coding
Elasticsearch 笔记
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-15
487
0
Coding
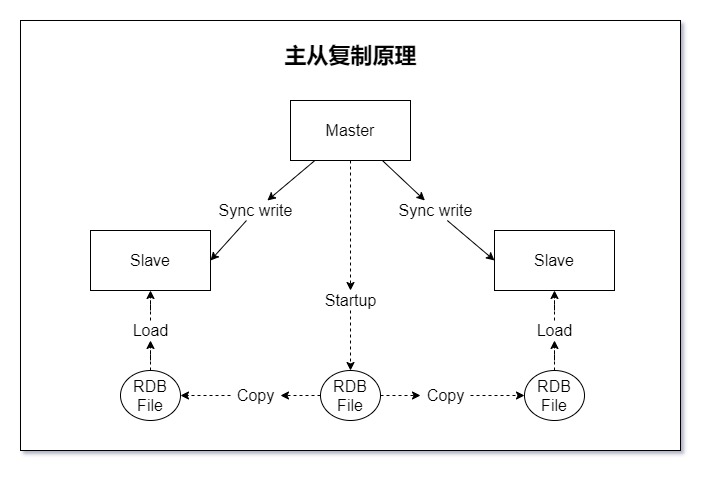
Redis 优化方案
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-14
451
0
Coding
Redis
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-14
325
0
Coding
Feign 接口中的类注解 @RequestMapping 被 SpringMVC 加载问题
本文采用知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 访问 https://creativecommo...
Post on 2020-10-09
559
0
X